本篇记录工作项目中经常使用的Docker和K8S命令,我所运行Docker和K8S的工作环境如下所示,大部分本文使用的命令都可以在Linux K8S和Windows10 K8S环境使用,少数命令存在预期结果不一致的地方,请自行查阅资料解决。
注意,这并不是一篇介绍Docker和K8S是什么的文章,入门课程请自行查阅官方文档学习;如果安装Docker和K8S环境也请自行查阅资料解决。
本篇记录工作项目中经常使用的Docker和K8S命令,我所运行Docker和K8S的工作环境如下所示,大部分本文使用的命令都可以在Linux K8S和Windows10 K8S环境使用,少数命令存在预期结果不一致的地方,请自行查阅资料解决。
注意,这并不是一篇介绍Docker和K8S是什么的文章,入门课程请自行查阅官方文档学习;如果安装Docker和K8S环境也请自行查阅资料解决。
Airflow pipeline作业流遇到这样一个问题:使用paramiko下载小文件成功,下载大文件出现Server connection dropped报错。
问题描述
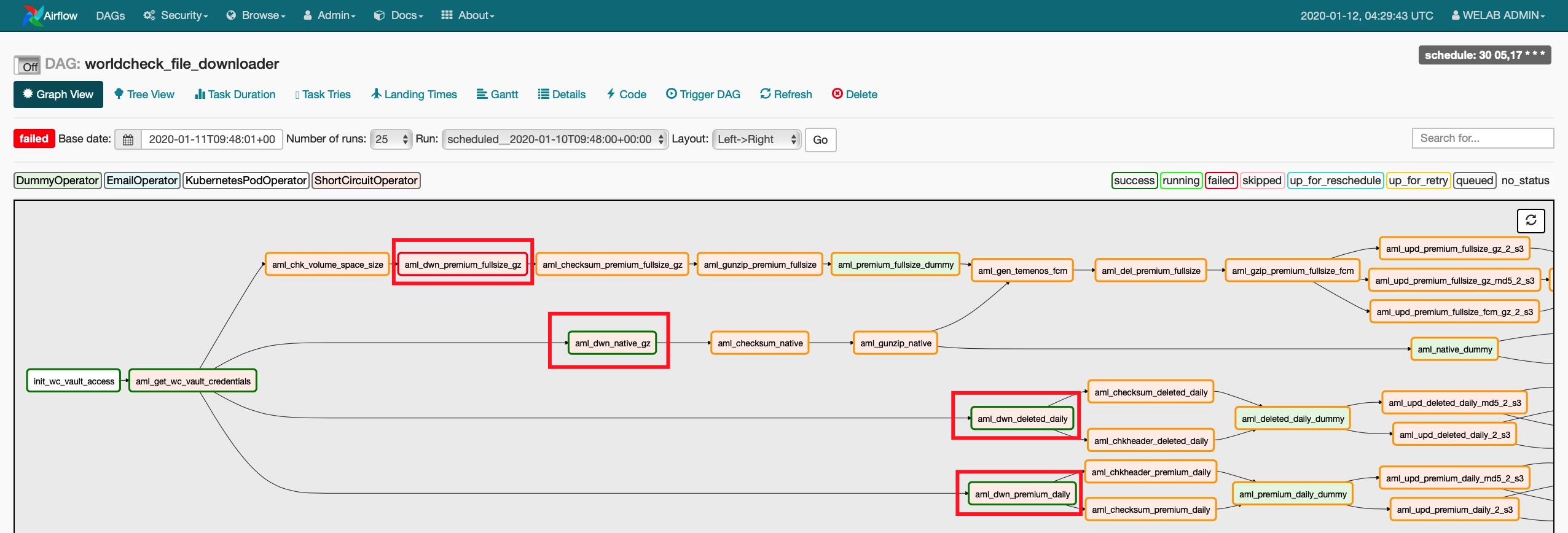
下图可以看到aml_dwn_native_gz、aml_dwn_deleted_daily、aml_dwn_premium_daily三个作业执行成功,但aml_dwn_premium_fullsize_gz出现报错。
Amazon AWS使用方法:
1.参照官网方法安装AWS-CLI
直接使用“pip install awscli”即可。
2.参照boto3 Documentation安装boto3
直接使用“pip install boto3”安装就行。
3.配置文件
先阅读官网,了解配置文件信息,进入终端:
使用”open -t ~/.aws/credentials”,先设置access token.

(Photo by Tianyi Ma on Unsplash)
客户需要用Python解决这样一个问题,读入一个3.4G大小的CSV文件,除首行记录外,将剩余行数记录中的K列,按照业务规则进行内容替换,处理完后生成一个新的CSV文件出来。
沟通了一番需求后,了解到CSV文件编码格式是”ISO 8859-1”;文件记录数大概有400多万行(拿到文件后我没敢用Excel打开看,怕卡死);首行是Header Cloumn,记录每一行数据的Layout;除首行外每一行记录都使用Tab键区分。
下面是我的分析思路:
CSV文件很大,不可能一次性读入内容,只能分块来读;首行是Header Column,读出来后需要单独标记不做处理;剩下400多万行中有一些需要替换(替换可以简单理解为将第K列的值由”Tencent”修改为”Alibaba”),具体哪些行,事先是不知道的;那最好就读一行处理一行。