最近遇到一个问题,在我的博客上点击“DataFrame”标签,程序跳转到“腾讯公益失踪儿童”页面,而不是预期的文章列表页面。
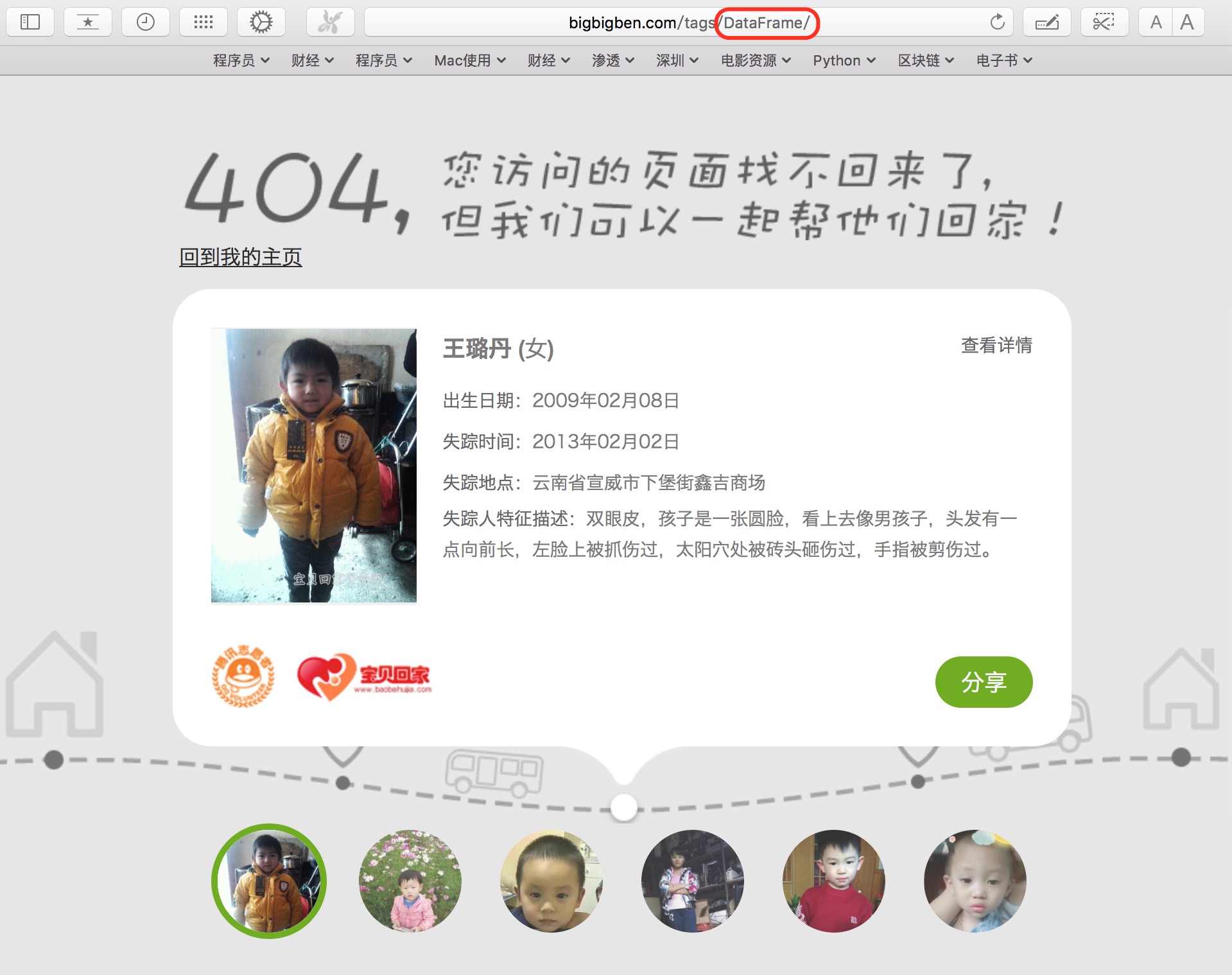
起初以为这是一个个例,但一番检查之后,发现一共有8个标签(下图红色方框标出)存在这个问题。
最近遇到一个问题,在我的博客上点击“DataFrame”标签,程序跳转到“腾讯公益失踪儿童”页面,而不是预期的文章列表页面。
起初以为这是一个个例,但一番检查之后,发现一共有8个标签(下图红色方框标出)存在这个问题。
半年前写过一个爬虫程序,用MongoDB作为持久化工具。今天把之前的爬虫程序整理一番,发现对MongoDB的操作有点生疏,在此做一个整理。
本文只讲解macOS系统下MongoDB的使用方式,版本号是v4.2.8,不涉及Windows或Linux系统,如果存在偏差,请自行查阅相关文档。
我们知道,mongodb启动的命令是mongod,它有两种方式启动,一是命令行带参数,二是配置文件方式。用命令行带参数启动方式比较简单省事,甚至你直接在终端里输入mongod就可以启动MongoDB服务(注意,这种方式启动成功的前提是已经创建好/data/db目录,并且设置成功相应的权限,/data/db目录是MongoDB默认存放数据的地方,就和MySQL一样数据库里每一条记录最终会存储在硬盘的某一个文件夹下面一样(在MySQL shell里输入show variables like '%datadir%'即可查看数据库对应文件夹的位置);只不过MongoDB需要自己先定义好)。
一般情况下,都应该使用指定配置文件方式启动。
命令行方式启动
这种方式就是启动的时候不用配置文件,配置文件里的配置项都直接写在命令行上。
mongod --dbpath=/usr/local/mongodb/data/ --logpath=/usr/local/mongodb/log/mongodb.log
命令行方式比较繁琐,而且需要手动敲一长串参数文件,不常用。
配置文件方式启动
将默认启动参数以yaml文件格式写到一个配置文件里。使用mongod -f /XXX/mongod.conf方式启动。
下面便是我使用的配置文件,路径我选择使用/usr/local/mongodb/etc/mongod.conf。
|
|
启动命令:
|
|
如果启动成功,在浏览器打开http://localhost:27017 ,能看到以下提示信息。
|
|
上面使用单机(Standalone)模式启动MongoDB,实际生产环境中,单机模式面临着很大的风险,一旦数据库服务出现问题,就会导致线上服务出现异常甚至崩溃,我们需要对MongoDB做相应的主备处理,提高数据库服务的可用性。这就是复制集(Replica Set)模式。
Replica Set是一堆mongod实例集合,它们有着同样的数据内容,包含三类角色:
注意,一个自动failover的Replica Set节点数必须为奇数,目的是选举投票的时候要有一个大多数才能进行选主决策。
贴两张图展示一下复制集模式,详细介绍请自行搜索查阅。
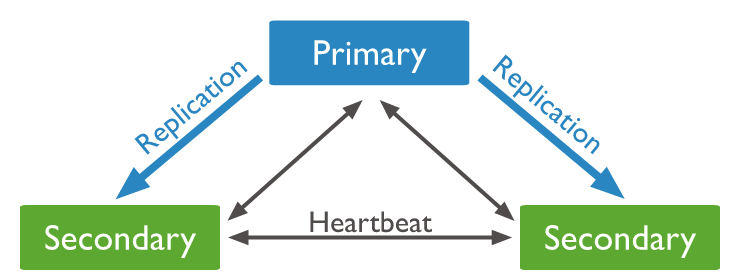
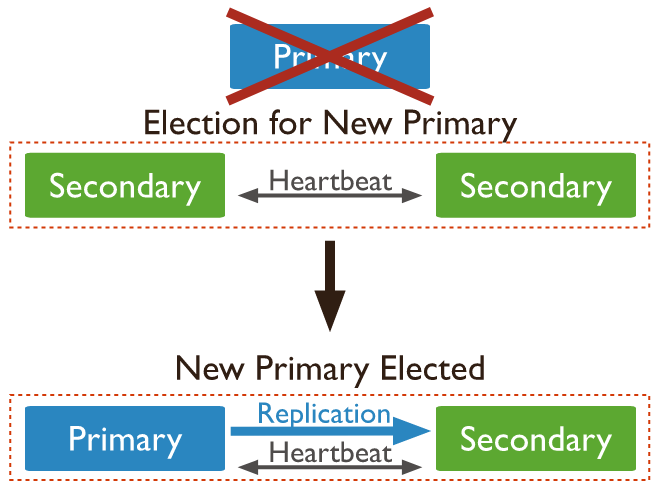
复制集模式,需要分别启动3个独立的mongod服务,我创建了一个新文件夹replicaset用于存放3个节点的数据,如下所示。
在/var/run目录下创建replicaset文件夹,在里面存放3个节点各自对应的PID文件。
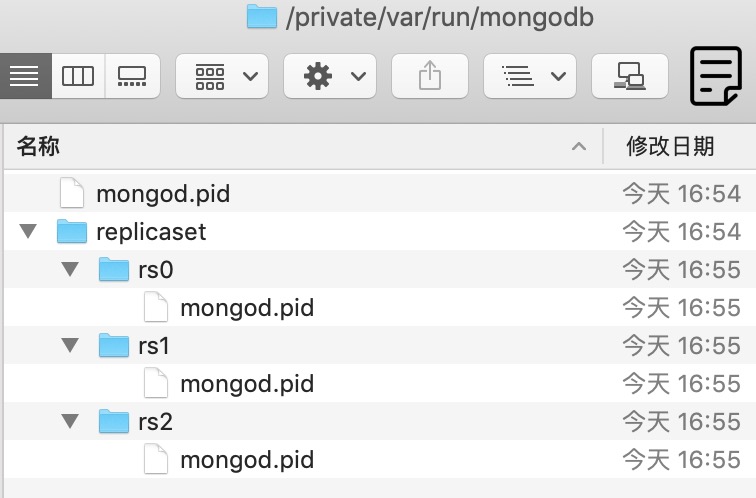
下面列出其中一个节点rs0的配置文件信息,rs1和rs2参照rs0配置即可,端口号依次用27017、27018、27019。
|
|
打开终端,依次执行下面3条命令,即启动了3个mongod后台服务。
mongod -f /usr/local/mongodb/replicaset/rs0/etc/mongod.conf
mongod -f /usr/local/mongodb/replicaset/rs1/etc/mongod.conf
mongod -f /usr/local/mongodb/replicaset/rs2/etc/mongod.conf
在终端输入mongo(不指定节点IP地址和端口号,默认等同于输入mongo 127.0.0.1:27017),输入rs.status()命令,可以看到replset当前没有初始化。
|
|
整理如下replset配置信息,执行rs.initiate(conf)命令,返回{ "ok" : 1 }表示节点部署成功。
|
|
部署成功后,会自动选举一个Primay节点。
输入rs.status()查看状态(我用......省略掉无效内容),可以看到members数组里有三个成员,stateStr代表节点的类型;health代表节点的状态,1表示健康;注意看27018和27019两个节点里有syncingTo这个参数,表示它们与27017保持同步。
|
|
注意:
如果以上部署不成功,将3个节点dbPath文件夹下面的内容清空重新部署即可。
上述操作都在27017这个节点的mongo这个shell里完成。
如果第一次只部署一个节点,第一个节点会默认设置为Primary节点;后续再添加的节点,会自动成为Secondary节点。
|
|
登录一个mongo终端(默认使用27017),执行rs.initiate(conf)成功后。
|
|
再依次执行rs.add("127.0.0.1:27018")和rs.add("127.0.0.1:27019")将另外两个节点加入rstest这个复制集,也可以得到和上面相同的结果。
进入Primary节点,写入数据:
|
|
进入Secondary节点,查看数据:
|
|
MongoDB连接字符串:
对于单机模式下的数据库连接,使用mongo://127.0.0.1:27017/test进行连接;
对于复制集模式,除了上面的方式外,也可以使用
mongodb://127.0.0.1:27017,127.0.0.1:27018,127.0.0.1:27019/test?replicaSet=rstest进行连接。
|
|
测试代码如下:
|
|
关闭方法:
使用./mongo进入shell控制台,输入use admin,然后输入db.shutdownServer()关闭服务。
直接kill进程号
参考资料:

(Photo by Goran Ivos on Unsplash)
今天使用Tushare获取个股的bar数据时,遇到这样一个问题。获取数据写入MySQL后,表里面date字段显示带有“00:00:00”格式,而且字段类型为datetime,如下图所示。
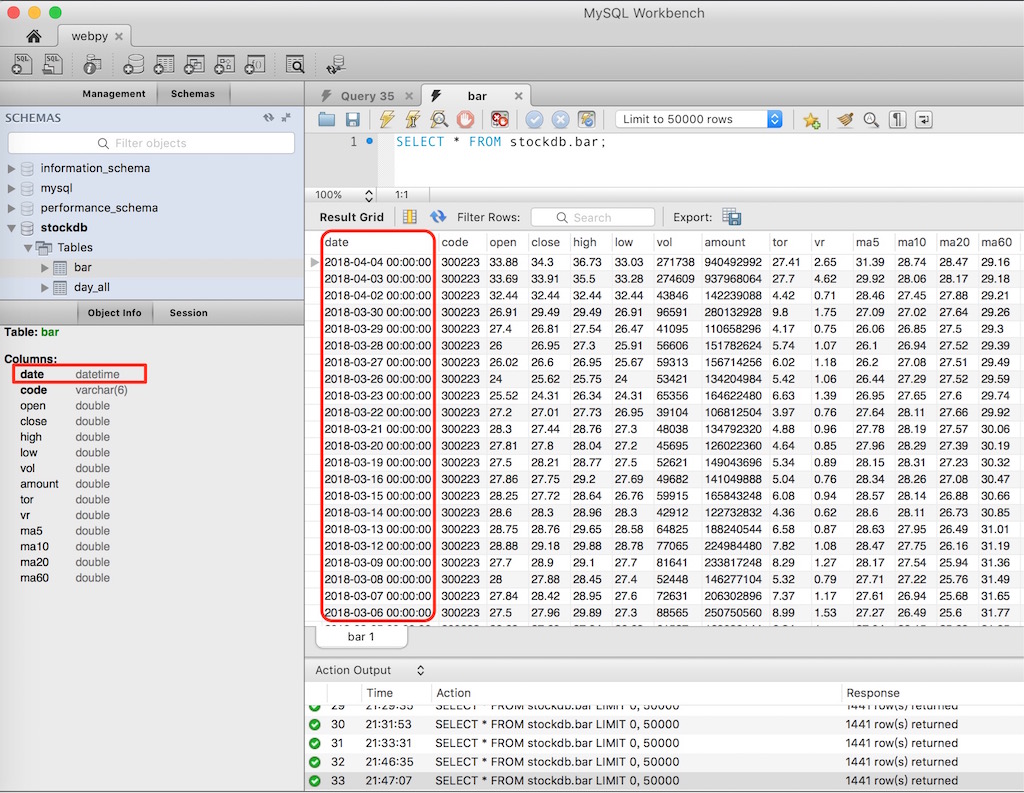
这或许没有什么问题,但和我预期的结果有差异,我预期date字段的数据类型是date,不希望它是datetime。并且,我不想date字段的值里面带有“00:00:00”这些内容。
排查原因,最后发现是Tushare包里面bar函数,获取到数据后,通过Pandas.to_datetime函数,将日期字段转换为带“00:00:00”格式的日期值。
见trading.py程序里面第861行,如下所示。
|
|

(Photo by Nghia Le on Unsplash)
上周五遇到pandas.DataFrame.to_sql写入Mysql数据库报错1170问题(详见:pandas.DataFrame.to_sql写入MySQL报错1170),卡了我一整天;周六联系Tushare作者米哥,在用户交流群里,发帖求助,米哥给了一些建议,我尝试了一下,报错依然存在;周日查SQLAlchemy Reference,在想是不是哪个参数没用对,看得要吐血了还是没有眉目;晚上和一个朋友聊天,他说他现在只用PostgreSQL,完全不用MySQL……
这句话给了我灵感,我把数据库换成PostgreSQL,结果会怎样?
上午来公司,安装PostgreSQL,熟悉语法,配置完后,拿原来代码直接一跑,我靠,直接成功。PostgreSQL没有像MySQL那样,创建索引时要求TEXT类型必须指定长度,我心里暗爽,即使MySQL报错1170问题无法解决,我可以用PostgreSQL继续完成我的股票分析大业啊。

(Photo by Fredrick Kearney Jr on Unsplash)
今天在使用pandas.DataFrame.to_sql这个接口,将Tushare获取的一个DataFrame写入MySQL时,出现如下报错。
PGM:writedb:write_records_into_mysql:error: (_mysql_exceptions.OperationalError) (1170, “BLOB/TEXT column ‘code’ used in key specification without a key length”) [SQL: u’CREATE INDEX ix_k_data_code ON k_data (code)’] (Background on this error at: http://sqlalche.me/e/e3q8)
这个错误在创建MySQL表时很常见,当键值字段是变长的BLOB或TEXT类型,MySQL引擎无法生成索引。
很遗憾,尽管知道原因,也尝试过几乎所有可行的办法,但就是没法解决。很无奈,编程工作就是如此,半年前的代码,核心程序不变,搁现在重构一下,就跑不通了。
心情灰暗了一整个上午,下面是报错详细内容。
最近在将半年前写的Python股票分析程序重构,打算写一个标准的Python包出来。write_records_into_mysql是所有程序写入MySQL的接口,它有两个必输参数,分别是df和table_name;三个默认参数,分别是conn、if_exists、dtype。
其它细节不贴,一眼就能看明白,这个函数主要作用是调用pandas.DataFrame.to_sql接口,将df写入数据库。to_sql接收的参数和write_records_into_mysql接收的参数其实是一样的,乍一看这里好像存在重复封装,为什么不直接调用to_sql写数据库,而要采用调用write_records_into_mysql的方式?这是一个好问题。