![]()
(Photo by rawpixel.com on Unsplash)
7月25日晚上看招财大牛猫的财经夜报,他提到过说“上市公司大股东,凡是股份有被司法冻结过,表明财务状况非常糟糕,建议投资者不要去碰”。

里面还特意提到可以去巨潮网查询“股份被司法冻结”的信息,当时看完就在想,这不就是我们Pythoner擅长干的事情吗。
进到巨潮网搜了一下,司法冻结相关的记录有3800多条;一开始担心HTML页面元素复杂,要翻380页,数据量有点大,用requests库实现的爬虫可能吃不消,在考虑是不是要用Scrapy框架。犹豫之中,用Chrome的开发者模式突然间发现巨潮网提供了非常友好的API接口,试着写了一个requests爬虫,一顿猛如虎的操作之后,所有目标数据就都搞到手了。
|
|
主程序是main函数,一个双层循环,将每个页面的数据提取后,添加到列表stock_list_all中,然后使用Pandas将其转换为一个DataFrame对象,最后将DataFrame导出到Excel表格。
Excel内容结果如下:
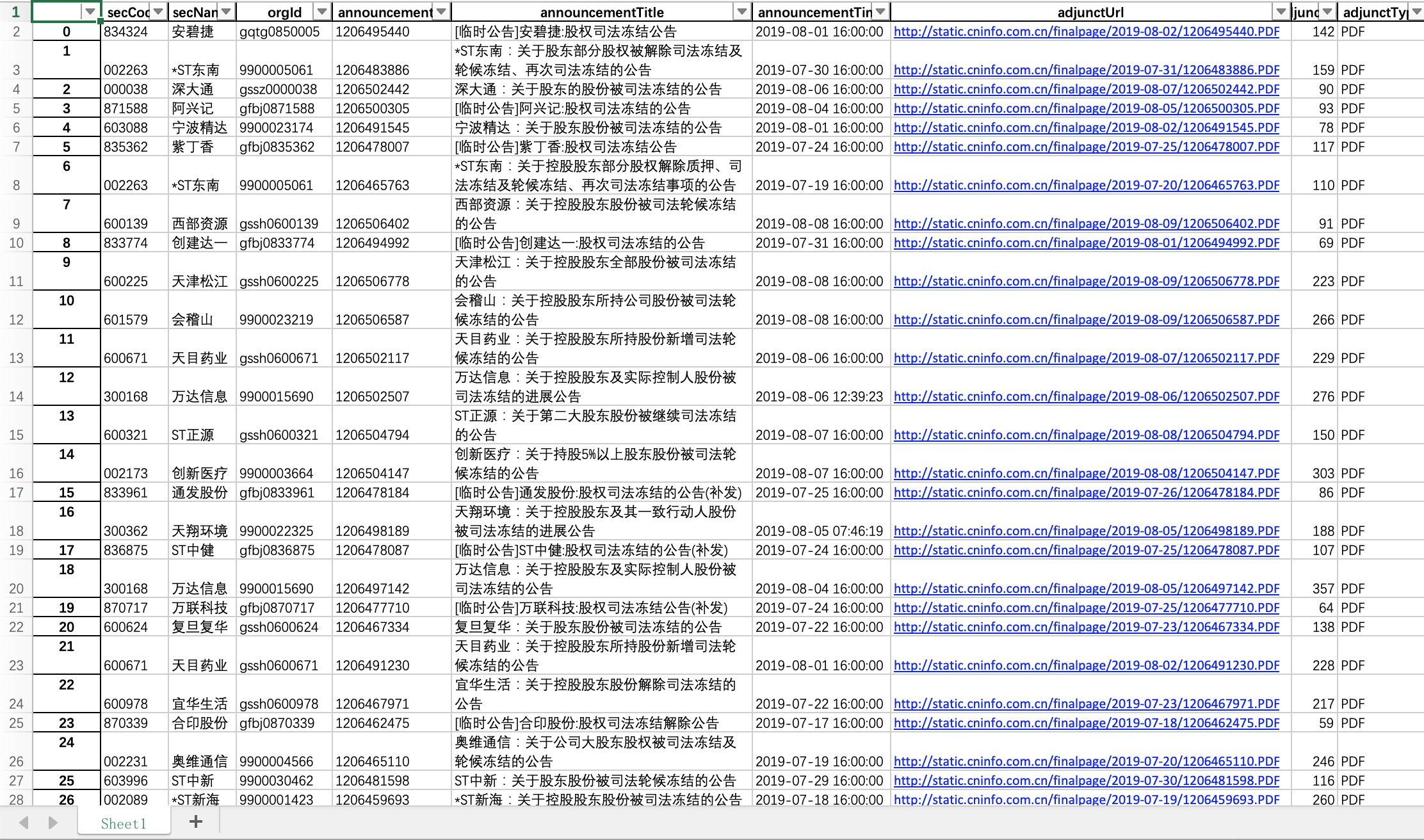
将股票代码、公司名称、被冻结时间、证监会公告PDF文档链接等信息都提取了出来。需要表格原件的请登录百度网盘下载,提取密码tf04。
使用双层循环实现之后,突发奇想如果用递归处理会怎么样呢,速度是不是会更快一些呢?递归处理过程中遇到一个大坑,详细见下一篇文章一个Python递归问题。
最终问题解决了,递归实现的源代码放在GitHub上,有兴趣的朋友自己去看吧。
