
(Photo by Goran Ivos on Unsplash)
今天使用Tushare获取个股的bar数据时,遇到这样一个问题。获取数据写入MySQL后,表里面date字段显示带有“00:00:00”格式,而且字段类型为datetime,如下图所示。
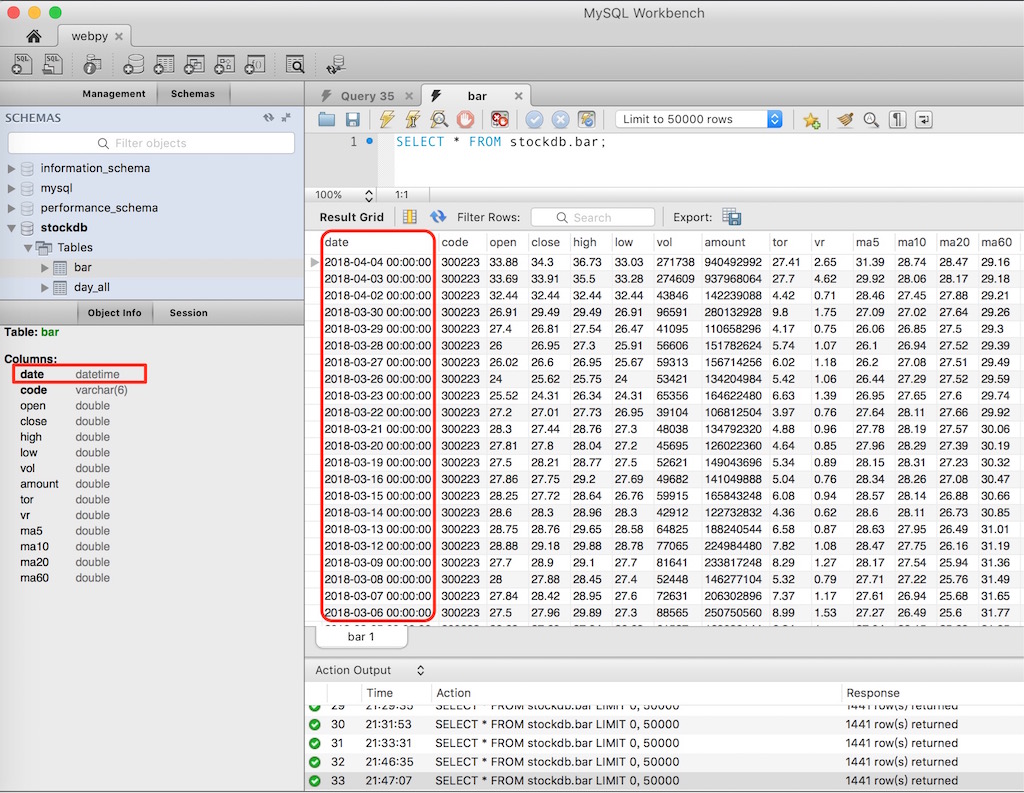
这或许没有什么问题,但和我预期的结果有差异,我预期date字段的数据类型是date,不希望它是datetime。并且,我不想date字段的值里面带有“00:00:00”这些内容。
排查原因,最后发现是Tushare包里面bar函数,获取到数据后,通过Pandas.to_datetime函数,将日期字段转换为带“00:00:00”格式的日期值。
见trading.py程序里面第861行,如下所示。
|
|
起初想直接修改这行代码,让它不返回带“00:00:00”格式的数据,有点遗憾,试过几个方法,都没能成功。在数据源头下手,其实是最好的方法,但目前功力不够,只能采用其它方法。
生成bar数据的原始代码如下。
|
|
其它方法,就只能是,生成带“00:00:00”格式的数据后,将其进行类型转换或数据拆分。
方法一,进行类型转换。
我们知道数据库里面“2018-04-04 00:00:00”这种格式的数据,属于Numpy的datetime64类型。因此我们的思路是先将其转换为Python自带的datetime类型,然后提取YY-MM-DD部分。以下是采取方法一后的程序代码。
|
|
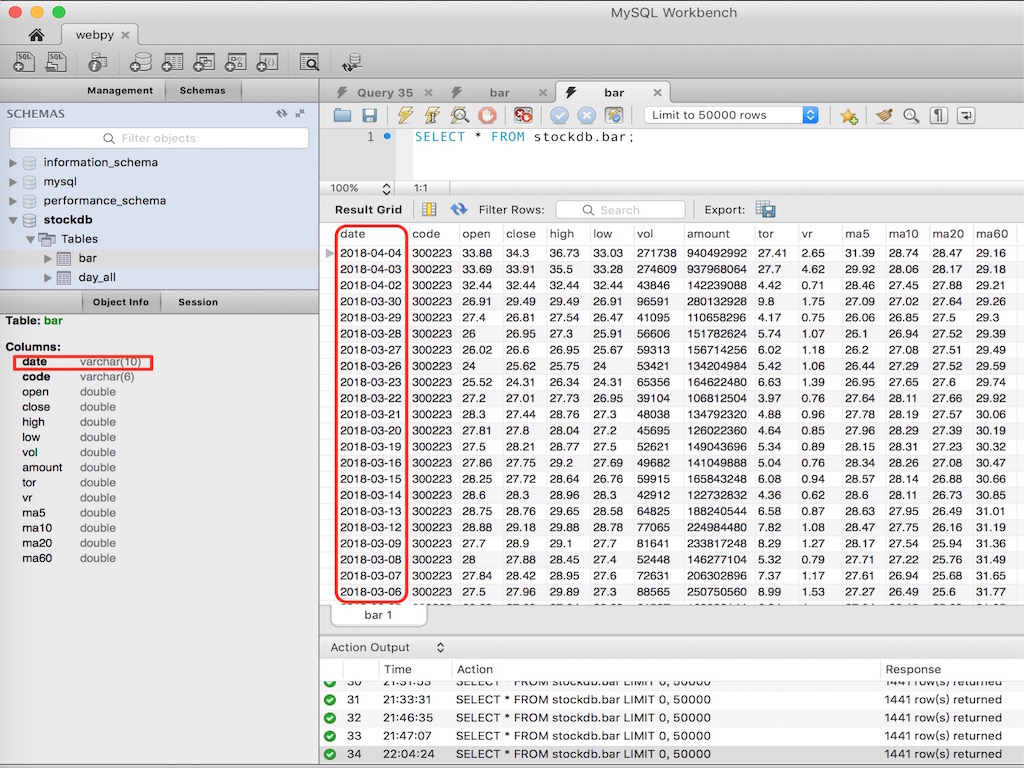
采用这种方法,能够解决问题,但生成出来的数据如下图所示,date字段它的类型变成了VARCHAR。并且,对DataFrame的index使用to_pydatetime进行类型转换,以及将date转换为VARCHAR类型,两步操作都挺影响性能。
方法二,进行数据拆分。
将Numpy的datetime64拆分为两个列date和time,date字段存放日期,time字段存放时间。以下是采取方法二后的程序代码。
|
|
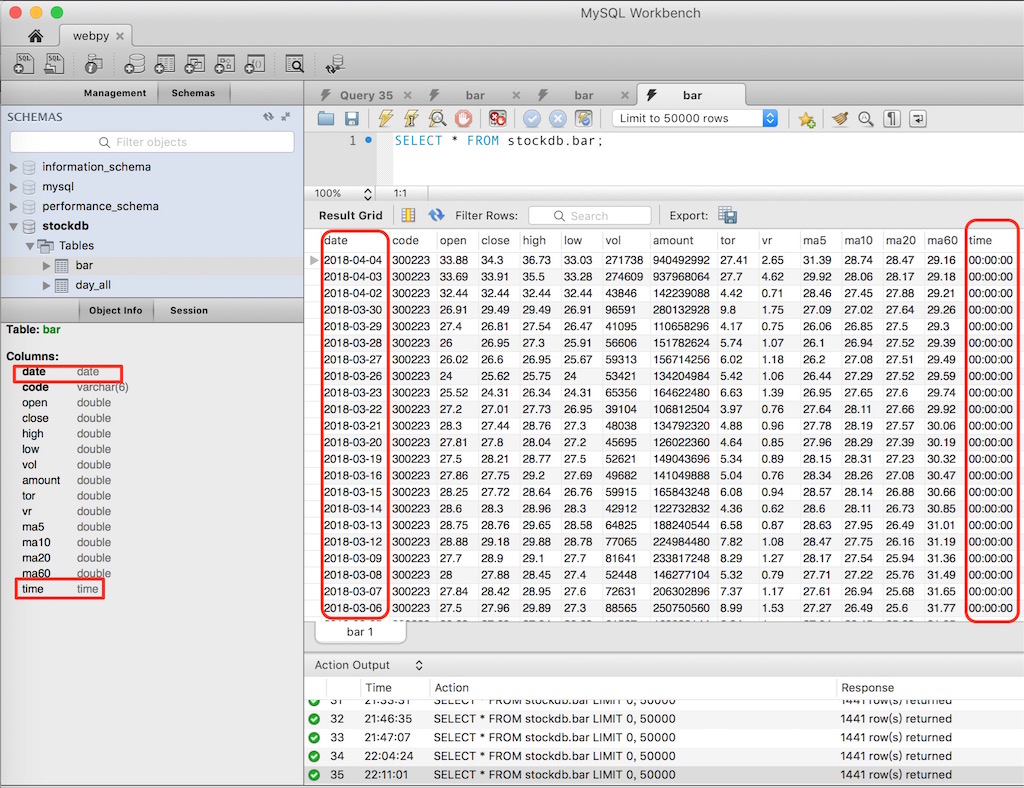
方法二生成结果如下图所示,效果比方法一要好,生成出来的date字段是预期的date类型,额外多出来的time字段,完全可以删除。
这个问题可能根本不是一个问题,因为date字段包含“00:00:00”格式,并没有导致程序出错;也不是说date字段包含“00:00:00”格式,数据就无法使用,只是我单纯觉得datetime类型没有date类型好、包含“00:00:00”格式的内容不易于理解,这两点不符合我预期才做出的修改。
如果从源头出发,可能会有更好的解决办法,以后找到方法再做补充。
参考资料:
