前两天整理使用Python爬虫下载电子书一文时,提过要给爬虫程序增加缓存处理。后面花了2天时间把Redis用法摸熟,然后在Mac上配置好了Redis环境。搭好环境后,发现那个爬虫程序其实非常简单,使出Redis有点大材小用,于是把Redis用在缓存股票数据上面,结果效果非常好。
关于Redis的缓存处理,我参考了陈皓老师缓存更新的套路文中提到的“Cache Aside Pattern”模式,来进行缓存设计,下面直接引用他博客里面的内容,非常受启发。
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
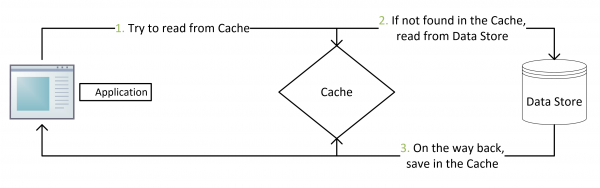
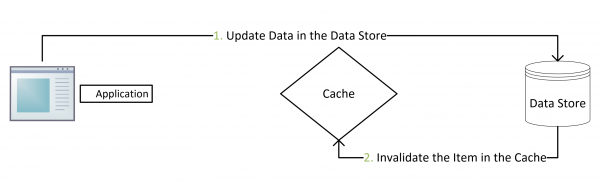
参考上面的两张图,在写数据库操作后面,增加写入Redis处理,代码块就不贴了;读取数据操作变成“先读Redis再读数据库”这种模式。
|
|
程序跑完后,查看写进Redis里面的记录,总共有91条。
|
|
查看Redis消耗的内存空间,目前总共102.76M。相比MBP 8G的内存,这点消耗还算好,如果哪天到了500M,可能就要采用LRU策略来对这些key-value数据进行处理了。
|
|
另外,使用Redis存储和读取DataFrame,在网上搜到如下方式,亲测有效。我采用的就是这种方式,至于有没有其它更好的方法,目前暂时没有时间去研究。
set:
redisConn.set(“key”, df.to_msgpack(compress=“zlib”))
get:
pd.read_msgpack(redisConn.get(“key”))
参考资料:
